前言
组件生命周期:
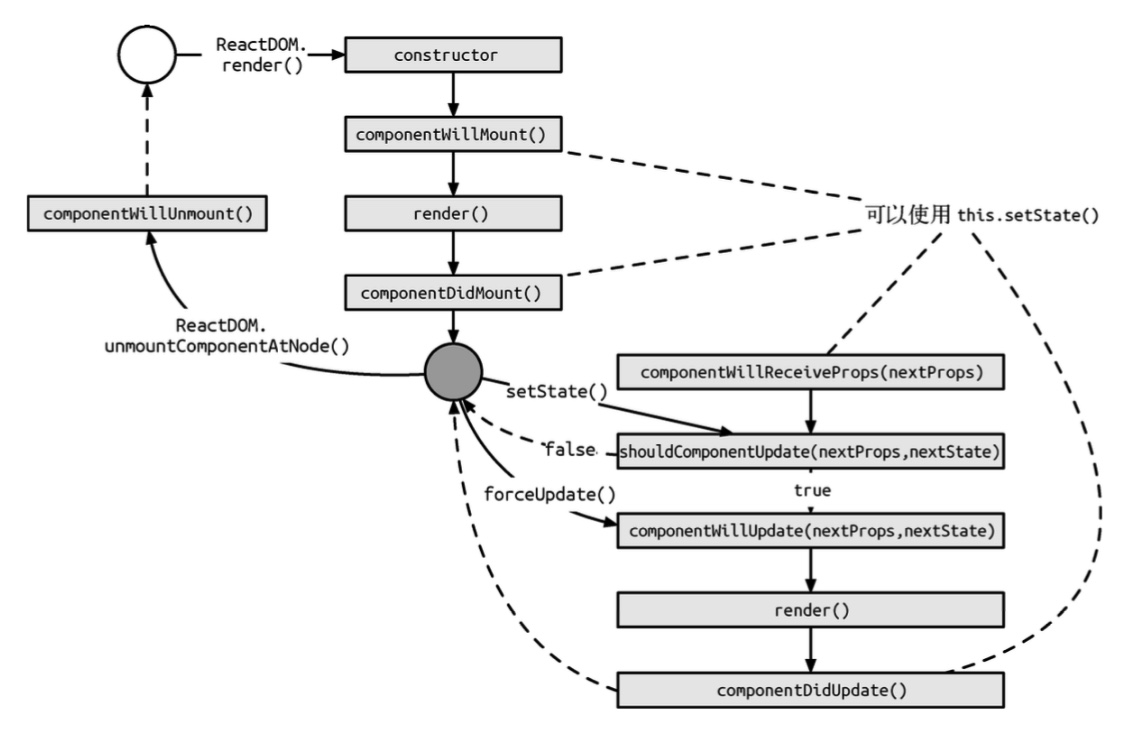
组件 render 分为两类:
- 初始 render:生成虚拟 dom 节点 -> 挂载节点耗时 = 业务逻辑计算时间 + 生成虚拟 dom 时间 + 挂载节点时间
- 更新 render:生成虚拟 dom 节点 -> diff 比较新老节点不同 -> 更新节点耗时 = 业务逻辑计算时间 + 生成虚拟 dom 时间 + diff 比较时间 + 更新节点时间
针对单个组件,优化的主要办法是避免重复执行 render 函数 与简化 render 内部计算。
针对整个组件树,优化的主要办法是优化组件结构和简化组件操作,这么做的目的是为了避免组件无用的构造、挂载和更新,减少 diff 算法的计算成本。
简化 render 函数内部计算
render 函数内部难免会涉及到一些业务相关的计算,不同业务场景,代码逻辑需要表达的计算方式不同。对 render 本身无用和重复的计算,会对整个 render 过程造成性能浪费。
render 中的业务代码计算优化方法与其他场景下业务代码计算优化方法并无差异,如遇到性能问题,以下有几点常用的 tips:
- 不要在 render 函数中写与 render 无关的业务代码,比如:
setState- 异步请求
- 内联函数的定义
- …
- 采用变量缓存的方法,避免在 render 函数中对某一变量进行重复计算,比如
- 对于大数组,避免重复读取数组的长度
- 将不直接或间接依赖 props 和 state 的变量计算逻辑放到 render 之外
- …
- 降低循环遍历带来的时间复杂度,避免重复循环,尽量将能在同一次循环迭代中完成的计算逻辑放到一次迭代中
- 延迟计算,很多时候由于条件判断的存在,某些计算的结果不一定会用上,建议将这部分计算过程放到真正需要它们的地方
- …
避免无用 rerender
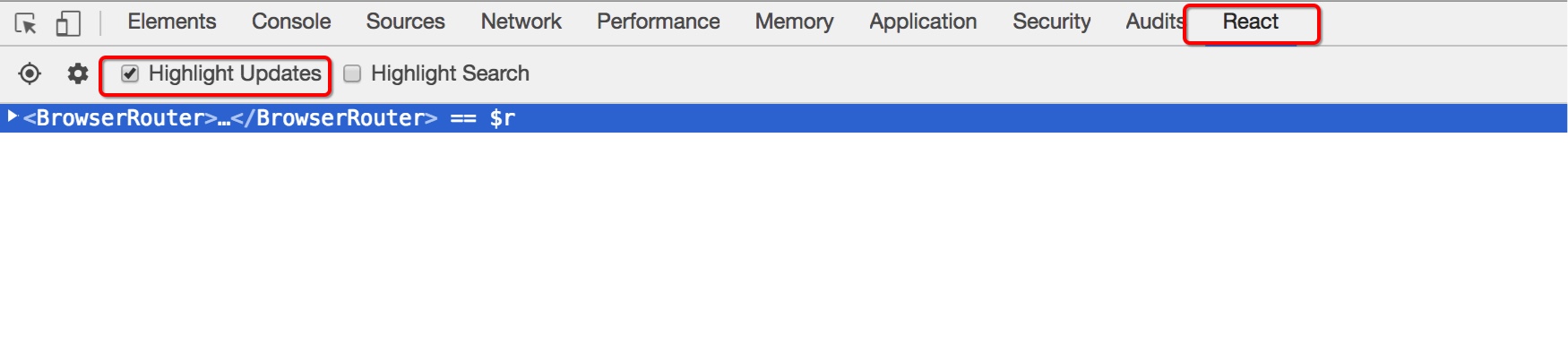
查看组件是否执行 render 的简易工具, 推荐 chrome 浏览器的 React 插件,使用方式(仅限开发环境):打开 chrome 控制面板,点击 React 插件并勾选 Highlight Updates 即可,然后在与 React 页面交互过程中,浏览器会自动高亮处于 render 生命周期的组件
触发组件 rerender 的条件(shouldComponentUpdate 以下简称 SCU):
- props change && SCU return true
- call setState && SCU return true
- call forceUpdate
- parent rerender && child SCU return true => child rerender
根据以上条件,分享几点 tips 帮助大家合理控制组件是否执行 rerender:
1. 当需要 setState 时再使用 setState
关于 setState 函数,官网有这么一段话:
setState() will always lead to a re-render unless shouldComponentUpdate() returns false
setState 函数设计初衷是为了让组件可以自由地设置内部状态,在 SCU 返回 true 的情况下,即使 setState 前后组件的状态未发生变更,setState 也会导致组件的 rerender,因此,请在需要更新组件状态的时候,再使用 setState 函数。
2. 控制 SCU 返回值
forceUpdate 函数会直接跳过 SCU,强迫组件 rerender,这种情况下,我们无法阻止组件 rerender,而另外三种条件均与 SCU 有关,只有在组件 SCU 返回 true 的时候,组件才能 rerender,因此,我们可以通过控制 SCU 的返回值来避免无用 rerender,即令 shouldComponentUpdate(nextProps, nextState) 在特定条件下返回 false。
3. 使用 PureComponent
react15.3 中引入了一个新类 PureComponent,它在 Component 类基础上,会自动根据 props 与 nextProps 和 state 与 nextState 的每个属性值是否相等来计算 SCU 的返回值,如果要使用 PureComponent,有几点 tips:
- 由于
PureComponent在比较 props 与 nextProps 和 state 与 nextState 每个属性值时采用的是浅比较的做法,因此对于复杂引用类型的属性值,PureComponent无法做到更深层次的比较判断 - 由于
PureComponent会对 props 与 nextProps 和 state 与 nextState 所有属性值进行比较,出于性能考虑,应该避免 props 对象和 state 对象体积过于庞大
优化组件树和简化组件操作
react virtul dom 和 diff 算法旨在有效地找出 UI 差异的最小集合,并把这种差异集合更新到真实节点上,diff 算法遵循两个原则:
- 不同类型的元素会产生不同的树
- 同一层级的一组节点,它们可以通过唯一 id(key) 进行区分
尽管 diff 算法十分高效,但它依然是一项耗时的工作,以下有几个 tips 可以帮助减少 diff 算法带来的开销:
避免无用的 dom 嵌套,尽量保持树的扁平
12345678910111213141516171819202122// badrender() {return (<div><Tab><p>错误做法:这种情况通常不需要在 Tab 外面再包一层 div</p></Tab></div>)}// badrender() {return (<div><div><div><p>错误做法:嵌套太多层 div </p></div></div></div>)}尽量避免节点的跨层级移动
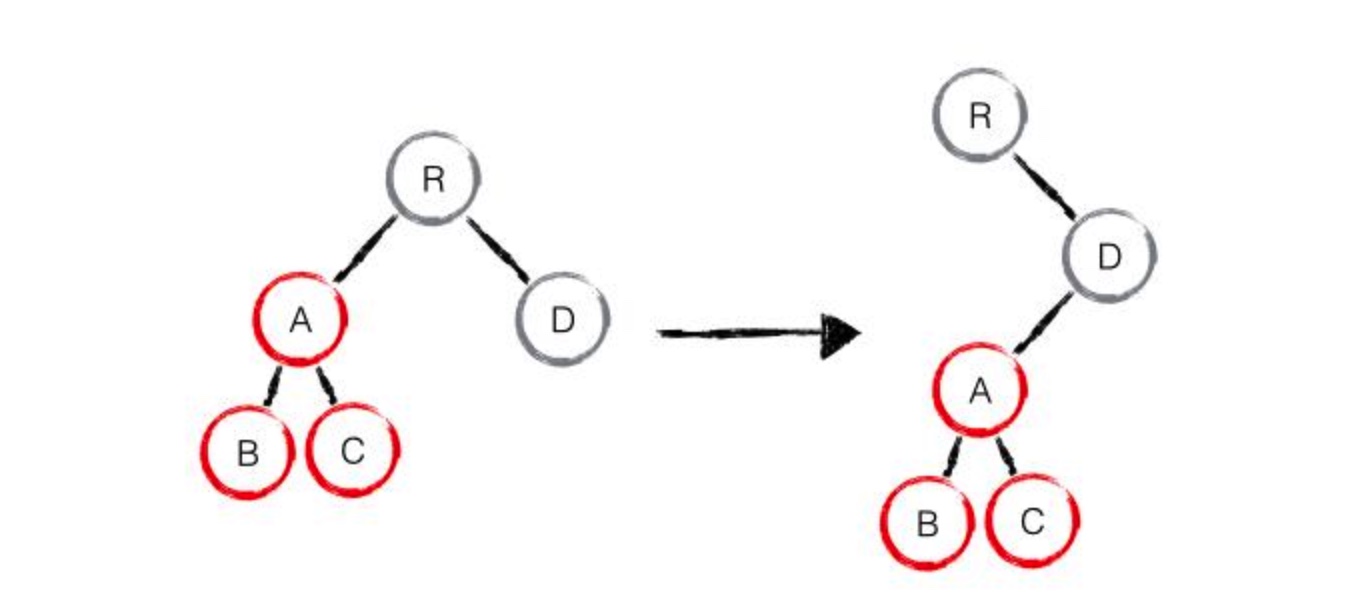
如下图,将 A 节点及其子树移动到 D 节点下面,由于 react 只会简单的考虑同层级节点的位置变换,而对于不同层级的节点,只有创建和删除操作。
这种情况下,diff 算法执行步骤为:create new A -> create new B -> create new C -> delete old A
更好的做法是通过 css 方式隐藏和显示节点,而不是真正的移除或添加节点。
同层级节点使用 key 复用老节点
考虑如下节点树操作,在原有节点 A B 之前插入一个 C 节点,diff 算法会按照自上而下的顺序依次比较 C A B 三个节点,针对是否使用 key 标识节点,diff 算法给出不同策略:
- 未使用 key 之前:delete old A -> insert new C -> delete old B -> insert new A -> insert new B
- 使用 key 之后:insert new C
未使用 key 之前,在头部插入 C 节点的时候,原有的 A B 节点被删除了,取而代之的是新 A B 节点,节点一多,在性能上就会有一定程度损耗,我们希望的是将原有 A B 节点保留下来,直接一步到位在头部插入 C 节点即可,react 提供了这种保留老节点的能力,即使用 key 去标识这些节点。
|
|
同层级节点使用唯一 key 值
很多时候,我们会通过数组类型的数据来创建一组同层级的节点,在创建过程中采用数组下标来设置节点 key 值,当遇到需要对数组重新排序(比如插入和删除数据)的情况时,数组下标与组件 key 值的对应关系可能会被打乱,导致部分原有节点无法复用,这些节点就会经历先删除再重建的耗时操作。
建议使用稳定,可预测且唯一的字段来标识 key 值,通常这种字段就是用来唯一标识数组元素的字段(比如元素 id),如果无法找到这类字段,可以考虑使用 uuid。
12345678910111213// 采用数组下标设置 key 值<ul>{items.map(({id, name},i) => <li key={i}>{name}</li>)}</ul>// 采用唯一 id 设置 key 值<ul>{items.map(({id, name},i) => <li key={id}>{name}</li>)}</ul>避免将同层级的尾部元素移到头部
考虑如下节点树操作,将同层级最后的 D 节点移动到头部。
移动前节点相对位置顺序为:A - B - C - D
移动后节点相对位置顺序为:D - A - B - C
移动前后,D 节点相对于 A B C 节点位置顺序发生了改变,最省时的做法是直接将 D 节点移动到头部即可,但 diff 算法对于这种相对位置发生改变场景的策略是:以相对靠后的元素为参照,移动靠前的元素。
基于以上策略,diff 算法会移动 A B C 到 D 之后,而不是移动 D 到 A B C 之前,因此,若 D 之前的元素较多,需要移动的元素也越多,性能开销也就越大。
123456789101112131415<!-- 移动前 --><ul><li key='a'>A</li><li key='b'>B</li><li key='c'>C</li><li key='d'>D</li></ul><!-- 移动后 --><ul><li key='d'>D</li><li key='a'>A</li><li key='b'>B</li><li key='c'>C</li></ul>
使用无状态组件
不同于有状态组件,无状态组件不会被实例化,没有标准的组件生命周期,占用的内存更少,整体渲染性能更优。关于无状态组件和有状态组件的区别,可参考如下表格:
| 无状态组件 | 有状态组件 | |
|---|---|---|
| 实例 | 没有 this 对象,无法访问 this.ref,this.state … | 可以被实例化,有 this 对象 |
| 生命周期 | 无法操控组件生命周期 | 自由操控组件生命周期 |
| 状态 | 不需要维护自身状态 | 需要保存和维护自身状态 |
| 创建方式 | 函数 | 类 |
使用 react production 版本发布引用
有统计表明,开发环境下 react 组件渲染性能会比生产环境下 react 组件渲染性能慢 2-8 倍,并且 react production 版本体积比 development 版本要小很多,建议在发布应用的时候使用 production 版本,使用方法:
直接在 html 头部引入后缀为
.production.min.js的 react 库,比如:12<script src="https://unpkg.com/react@16/umd/react.production.min.js"></script><script src="https://unpkg.com/react-dom@16/umd/react-dom.production.min.js"></script>webpack 方式:在配置文件中加入
1234new webpack.DefinePlugin({'process.env.NODE_ENV': JSON.stringify('production')}),new webpack.optimize.UglifyJsPlugin()
结合 Redux 的性能优化
由于每次组件的 rerender 都会触发 connect 函数的重新计算,因此简化 connect 函数计算十分重要: